
Troubleshooting Non-Indexable URLs In Screaming Frog
Recently I came across an issue which took me a while to find an answer to.
I was doing a site migration (same domain, new URLs) and ran a Screaming Frog crawl across the new site when I noticed something a little odd.
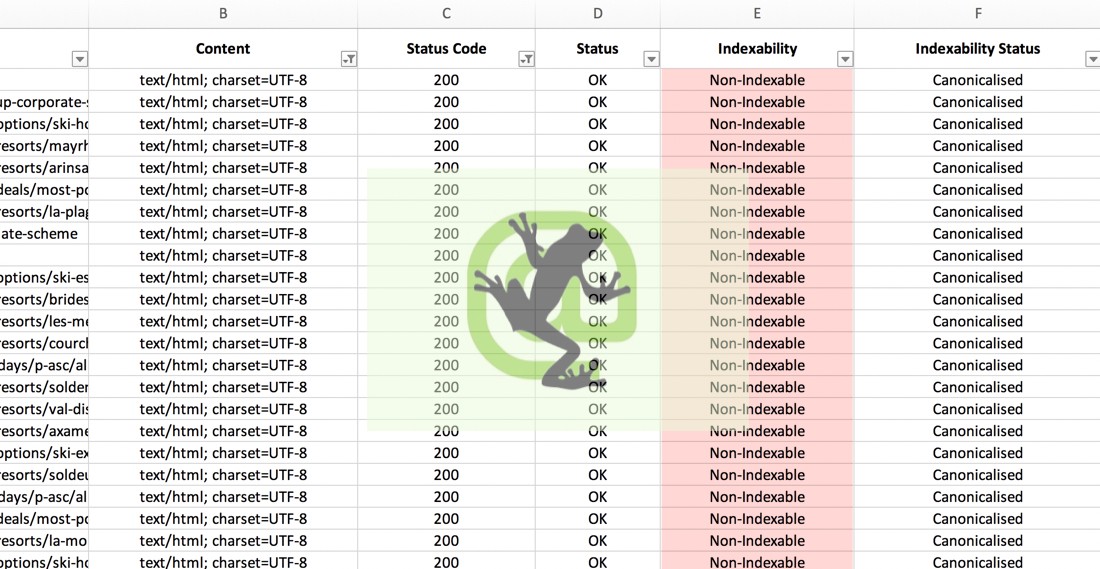
All the new html URLs that had a status code of 200 and had a status of ‘OK‘ seemed to be non-indexable. The URLs were canonicalised. I scratched my head.
According to Screaming Frog, a non-indexable URL indexability status can be attributed to one of the following issues. The URLs:
- Are blocked by robots.txt.
- Give no Response.
- Redirect (3XX, meta refresh, or JavaScript redirect)
- Give Client Error (4XX)
- Give Server Error (5XX)
- Are Noindex (or ‘None’)
- Are Canonicalised
- Are Nofollowed
I checked everything. The robots.txt file wasn’t blocking the URLs, there were no redirects, meta refreshes or client errors, noindex tags weren’t present, and nofollow tags weren’t present.
Puzzling. And troubling.
That only left a potential issue with the canonical link element.
I doubled checked the canonical links on a couple of the pages, and finally spotted the answer.
The new canonical tags were referencing ‘HTTP’ rather than ‘HTTPS’. As a redirect was in place from HTTP to HTTPs for all URLs, this led the SEO spider to flag the URLs as non-indexable.
The canonical tags were changed to HTTPS and voila, problem solved!



Hi Simon,
I’ve bumped into this post searching for this exact same issue. The odd thing is that the canonical tags are referencing https. So there should not be a redirect issue right? What I don’t understand is that every non-indexable / canonicalised page has two canonical link elements. Link element 1 is referencing to the Homepage. Link element 2 is self referencing. Any thoughts on this? thx
Hi Robbert, that does sound a bit weird. In fact that would be the reason Screaming Frog is pushing out an error. A page should only have one canonical tag – if a page has multiple canonical tags, then Google will ignore both (see more here > https://webmasters.googleblog.com/2013/04/5-common-mistakes-with-relcanonical.html). Try just the self-referencing canonical & see if that works 🙂
Hi Robbert and Simon,
Just want to say, I am doing an audit of a website and encountering this issue, too. What I found out was that my site has in some cases redirect chains with up to 6 hops, which I believe is why some of the URLs although 200/OK and canonicalized were marked down non-indexable.
Thanks, Simon, for starting a discussion about this. Definitely a super interesting topic!
Thanks Lazarina, that would make sense! Hopefully the blog post or your comment will help clear up any issues. Thanks for commenting 🙂
Hi Simon
I have the exact same issue and yet the site in question appears to be successfully indexed on Google nonetheless. Did you spot any actual issues arising from this problem (the http instead of https in the canonical tag) or was it just about fixing a reporting problem inside Screaming Frog.
Thanks in advance.
Ben
Hi Ben, thanks for commenting. Interestingly some of the pages were indexed on Google also, but for best practice purposes I wanted to ensure everything was set up correctly, so ensure the canonical tag issue was fixed (it wasn’t an issue with Screaming Frog). Cheers, Simon
I’m having this exact problem with several sites of my employer. 90-99% of the URLs are non-indexable canonicalised, but also OK and 200 (according to Screaming Frog tool). However, we do score in Google.
The only difference I notice it the / at the end of the URL. Could that be it? It’s not Http(s).
Frog also says:
Meta Robots 1 – ALL
Meta Robots 1 – ALL,INDEX,FOLLOW
Could it still affect SEO?
Hmm, strange one. If the content is being indexed, then that’s a good start. Yes, check the trailing slash to see if that is the cause.
One other thing: I checked like 10 sites for this issue, from competitors to very big sites, none seem to have this issue. Except for the site of the (large and succesful) company that created/hosts our sites and the site of their marketing partner (who’s also responsible for a lot of our content)!
I have a similar problem, but canonicalized URL is HTTPS. The canonical link element is indexable. When I checked the cached version it was also cached properly, however rel=”prev” 1 is not cached. What should I do get all elements cached and Indexed?
Hi everyone,
I have also done audit for my website and the odd thing is that the canonical tags are referencing https. So there should not be a redirect issue, right? What I don’t understand is that every non-indexable / canonicalised page has same URL for address as well canonical link elements.what is that error ? confused?